
I have been a big fan of machine learning for 4 years and deep learning for more than a year. I built predictive model for fun and work. I know a lot of algorithms, from the conventional one like gradient boosting to the deepest model like LSTM. Despite numerous algorithms I had acquired, my puzzle remains.
Puzzle That Algorithm Itself Cannot Solve
If you are not the kind of data scientist who only cares how to reduce that 0.01% error but try to make sense of your model, you might have questioned yourselves from time to time:
Over the time, I have built up enough sense to tackle these fundamental questions, for example, I know bi-variate relationship can be very different from multi-variate relationship or the data is subject to selection bias. But it lacks a solid framework that I could convince myself definitely and others. More importantly, I might not be aware until a relationship contradicts my sense! Important to note, when something contradicts, it has already gone very wrong. Without a map, how can I be sure I am not heading to the wrong destination before I know I am lost?
Yes, Both Association and Causality Can Predict
The puzzle has completely gone when I read “The Book of Why” by Judea Pearl. Now it is my guide for data science. Here I will tell you WHY briefly. In short, it is causality, the relationship between cause and effect. To predict something in the future, there are two ways:
Both ways can predict. Both ways might yield similar model performance. So, what is the difference? Why bother to understand causality? And if it is a more powerful tool, can causality be studied via data?
Random Controlled Trial and Why It Is Not Practicable Sometimes
As a gold standard, randomized controlled trail (RCT) (or so called A/B test in marketing) is used to test for causality. Particularly, in clinical trial, this technique is used to study whether a particular medicine/ treatment can improve health.
Randomization is to minimize selection bias, so that we know, for example, we do not selectively apply treatment to more ill patient, resulting in an apparently lower benefit that it wouldn’t be if we did not select more sick patient. Control is to act as a benchmark so that we can compare patient that did receive treatment vs patient who did not receive a treatment. As a standard, there is also a so called double blind mechanism, so that the patients did not know whether they actually receive treatment or not, in order to screen off psychological effect.
While it is a gold standard, it might not be practicable in some circumstances. For example, if we want to study the effect of smoking on lung cancer, apparently we can’t force someone to smoke. Another example: if I want to know how far I would go if I did a PhD, definitely it is not possible as time will only go forward. After all, an experiment is subject to a lot of limitations, for example, whether the sample can represent the whole population, whether it’s ethical, etc.
From Observational Data to Causality Analysis?
If it is not practical to conduct an experiment, can we use the observational data to study causality? The observational data means we can’t do any intervention, we can just observe. Is that possible?
No matter you know statistics or not, you might have heard the saying that correlation does not imply causation. However, it does not tell you how to study causality. The good news here is ,after reading this book, you will have a better framework of how to study causality, and determine when you can or cannot study it given the data you have and therefore you know what data you should collect.
Takeaways From The Book
I am not covering the detailed techniques or formula here. On one hand, I just finished reading this book and I am no expert of causality; on the other hand, I encourage you to read the book in order not to miss any insight because I might have bias.
Despite the prominence of big data, it might be wrong to add everything into your model
In the era of big data, with virtually unlimited computational power and data, you might be tempted to put every data into a deep neural network for auto feature extraction. I was tempted too.
This book tells you a few scenarios that adding certain variable needs caution. For example, you want to predict Z, and the underlying relationship is X →Y → Z (arrow denoting “causes” and in this case Y is a mediator, which mediates effect from X to Z). If you add X and Y as your variables in your model, Y might absorb all the “explanatory power”, which kicks X out of your model because Y is more direct than X from the perspective of Z. This prevents you from studying the causality between X to Z. You might argue, there is no difference in prediction, isn’t it? Yes, from the viewpoint of model performance, but what if I tell you Y is so close to Z such that by the time you know Y, Z already occurred.
Likewise, not adding certain variable is risky. You might have heard of the term spurious correlation or confounding. The basic idea can be illustrated in this relationship, Z← X → Y (i.e. X is a confounder). Note that there is no causal relationship between Z and Y, but if you don’t consider X, there appears to be a relationship between Z and Y. A famous example is the positive correlation between chocolate consumption and no. of Nobel Prize winner. It turns out that the common cause is the wealthy of a country. Again, you might have no problem of prediction, but you probably have a hard time to explain your model to others.
Of course, the world is more complicated than we thought. But this is where domain knowledge plays in and causal diagram is a simple yet powerful representation of how everything works.
There are more advanced brain teasers and real life examples in the book. Fortunately, the rules provided make them easy to follow.
Causality might be more robust
Causality might change over time. If you want your model to be robust over time. Taking Z← X → Y as an example, if the relationship Z← X has weakened, it wouldn’t impact you if you model X → Y, but it would if you model Z and Y.
From another perspective if we believe causality is a stronger relationship than association, it means that relationship is more likely to hold if we borrow it from one area to another. This is so called transfer learning/ transportability, as referred in the book. The book quotes a very insightful example of transportability, and it describes how we can transparently perform adjustment so that we can transport the causal relationship from one area to another.
Intervention becomes much easier, particularly in the digital age
Intervention is actually one of the great motivations of studying causality. Predictive model by learning association alone cannot give you insight to intervene. For example, you can’t change Z to impact Y in Z← X → Y, because there is no causal relationship.
Intervention itself is a much more powerful tool as you can understand the underlying relationship. This means, you can change government policy to make our world a better place; you can change treatment to save more patients, etc.. This is difference in you saving the patient vs you predicting the patient will die but can’t intervene! Perhaps this is the best thing a data scientist can do, only with this toolkit!
In this digital age, intervention takes less effort, and for sure, you have more data to study causality.
It is how we reason and as such it might be the route to real AI
Finally, it is about artificial intelligence. Reasoning is a necessary part of intelligence and it is how we feel. In a closed world, with well defined reward and rules, reinforcement learning achieves excellence via a balance of exploring and exploitation to maximize pre-defined reward under the pre-defined rule, and under the mechanism that the action taken changes the state which in turn determines the reward. In this complicated world, this mechanism is less likely to hold.
From a philosophical perspective, we should understand how we make a decision. Most likely, you will ask, “If I do this, what would happen; if I do that, then?”. Note, you just created two imaginary worlds that has not happened. Sometimes, when you do some reflection to learn from mistake, you might ask, “If I had done this, that would not happen.” Again, you created your counterfactual world. Indeed we are more imaginative than we thought. And these imaginative worlds are built on causality.
Perhaps robot might have their own logic, but if we want it to be like us, we need to teach them reasoning. It reminds me of a paper published by DeepMind, “Measuring abstract reasoning in neural networks” (link), which shows adding the reason as part of the training data can enhance generalization. I was deeply inspired by this paper, this is exactly the case where we teach robots reasoning! And it is a leap from association in pattern to reasoning.
I conjecture that causality helps generalization. I don’t have a proof, but this is how we makes sense of the world. We are taught with one or two examples, then we learn the casual relationship, and we apply this relationship wherever we think it is applicable.
Putting everything into a casual diagram, perhaps reasoning is the confounder of question and answer of IQ test? Can we argue reasoning causes one to design those pattern in the question, and it also “causes” the answer? Alternatively, it can be a mediator that translates the question into reasoning, which in turn causes the answer? Or it could be both? Note that I deliberately assume no casual relationship between Question and Answer as they are purely pattern association.
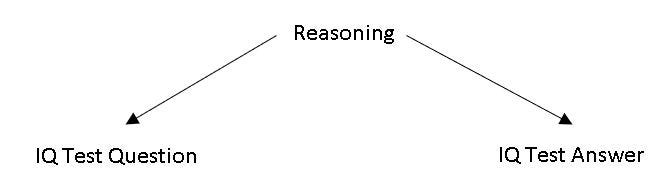

They are just my wild guesses. I don’t know the answer. I am not a full time researcher nor a philosopher. But what I am sure is that causality provides a new perspective when we attack a problem. The synergy between causality and deep learning sounds promising.
Final Thought
I admit that the topic of this article might be a bit aggressive, but I feel duty-bound to recommend this book to everyone. It tells us the full potential of causality, something inborn with us but we might overlook in the era of big data. The framework, do-calculus, is already there. It just waits for us to deploy and put it into practice.
As a practitioner, with this powerful tool, I trust we can make a better impact.
<hr><p>Why every data scientist shall read “The Book of Why” by Judea Pearl was originally published in TDS Archive on Medium, where people are continuing the conversation by highlighting and responding to this story.</p>